prévisions
La prévision est un des objectifs de la régression, et particulièrement de la régression linéaire. C’est une procédure apparemment simple, mais elle nécessite en fait d’avoir bien compris le modèle linéaire, la nature des estimations que l’on obtient et les propriétés des prévisions effectuées.
Les applications « Prévisions… » donnent la totalité des résultats concernant une prévision et donnent la possibilité de discuter de la nature de la prévision et de sa validité.
Nous considérons dans l’exemple ci-dessous la régression du revenu par l’âge des clients d’Euromarket : nous considérons tout d’abord toutes les données (ce qui, nous le savons, n’est pas bon), puis éliminons les trois clients 25, 31 et 43 (le modèle linéaire devient admissible).
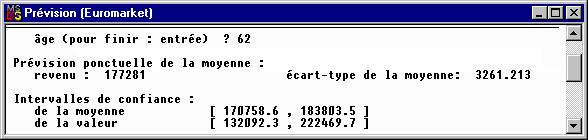
Effectuons la prévision des revenus des clients de 62 ans, soit l’âge du client 25. Il faut d’abord indiquer la valeur du t de Student pour calculer les intervalles de confiance suivant le niveau de signification choisi (ou le risque de première espèce a). Pour un degré de liberté égal à 40 et un niveau de confiance de 0.95 (soit un risque a = 0.05), la table donne t = 2.021. Nous prendrons pour simplifier la valeur 2 sans plus nous préoccuper du degré de liberté toujours de l’ordre de 45. La prévision du revenu des clients de 62 ans est donnée par les résultats ci-dessous :

Comment interpréter ces résultats ?
· La prévision ponctuelle est la valeur proposée de la moyenne des revenus des clients de 62 ans
· le premier intervalle de confiance contient cette moyenne, avec un niveau de confiance de 95%
· le second intervalle contient les revenus de 95% des clients de 62 ans.
La représentation graphique ci-dessous justifie l’exclusion des clients de rangs 25, 31 et 43 :

On peut alors recommencer la procédure de prévision :
. 
Les estimations sont très différentes des précédentes. La question qui vient à l’esprit est la suivante : quelles sont celles qu’il faut choisir ?
La réponse est simple : aucune. En effet :
· dans le premier cas, le modèle n’est pas linéaire. La prévision par la droite de régression n’est pas bonne.
· dans le second cas, le modèle est linéaire mais les clients en retraite ont été éliminés (pardon pour eux !). On ne peut effectuer de prévision pour 62 ans, valeur qui sort de l’intervalle dans lequel le modèle linéaire est valide.
D’où une nouvelle question : comment faire ? On peut proposer comme prévision la moyenne des revenus des clients de plus de 60 ans soit 78 777F : il n’existe guère en effet de relation entre l’âge et le revenu à partir de 60 ans. La variance de ces revenus permet de calculer l’intervalle de confiance de la moyenne, et, si leur répartition est normale (suit la courbe en cloche), l’intervalle de confiance des valeurs. Le faible effectif que nous avons ici enlève tout intérêt au calcul.
|
rang |
âge |
revenu |
|
25 |
62 |
76865 |
|
31 |
68 |
86468 |
|
43 |
67 |
72999 |
La procédure de prévision que nous avons effectuée précédemment est ainsi pleine d’enseignement. Les prévisions effectuées de la taille des étudiantes par celle de leurs pères (ou de leurs mères) présentent beaucoup moins de difficultés. On pourra d’ailleurs procéder à des expérimentations de la façon suivante :
· effectuer des prévisions individuelles et les comparer aux valeurs réelles ; on observe des erreurs fréquentes.
· collecter des valeurs réelles des variables expliquée et explicative et effectuer la prévision de toutes ces valeurs ;
· calculer la moyenne des carrés des erreurs et la comparer à la variance des valeurs collectées précédemment .
En principe - mais on ne peut jamais en être certain -, la moyenne des carrés des erreurs est inférieure à la variance, considérée ici comme la moyenne des carrés des erreurs lorsque l’on remplace la taille des étudiantes par sa moyenne. On obtient donc un gain dans la prévision.
L’intérêt de cette dernière procédure, possible par le logiciel de régression linéaire de StatPC, est de montrer que la régression n’améliore les résultats que sur un nombre relativement important de données, et que rien n’est moins sûr sur un individu particulier.